
[운영체제] 영속성에 관하여1 - I/O 시스템
I/O 장치
본론 (영속성)에 들어가기에 앞서 먼저 입력/출력 장치 의 개념을 알아보자. 우리가 해결해야 할 문제는 다음과 같다.
핵심 질문 : 어떻게 I/O를 시스템에 통합할까?
시스템에 I/O를 어떻게 통합해야할까? 일반적인 방법은 무엇일까?
어떻게 효율적으로 통합할 수 있을까?
A. 시스템 구조
<시스템 구조="" 모형="">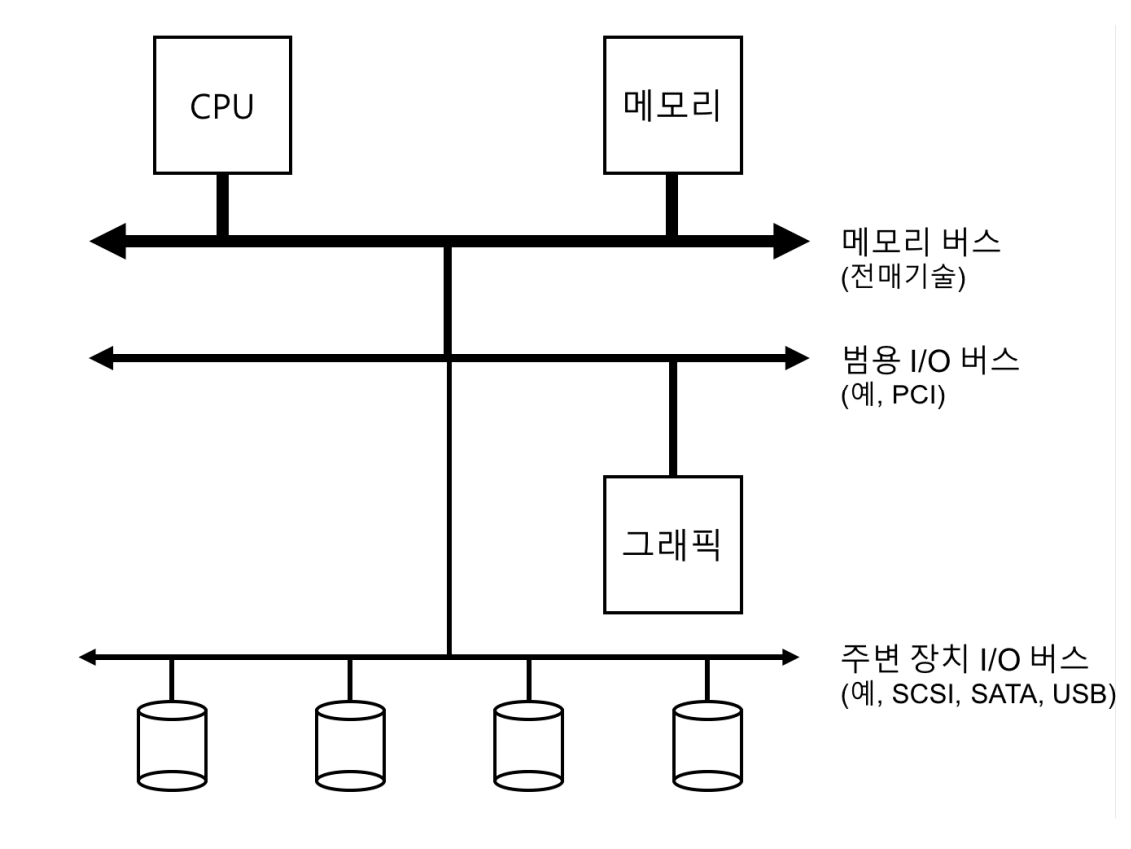 일반적인 시스템 구조에서 CPU와 주메모리는 **메모리 버스** 로 연결되어 있다. 몇 가지 장치들이 PCI같은 범용 **I/O 버스** 에 연결이 되어있다. 그래픽이나 다른 고성능 I/O 장치들이 여기에 해당한다. 그리고 그 아래에는 SCSI, SATA, USB와 같은 주변장치용 버스가 있다. 이 버스들에 디스크, 마우스와 같은 가장 느린 장치들이 연결된다.
계층적인 구조가 필요한 이유는 물리학적인 이유와 비용 때문이다. 버스가 고속화하려면 더 짧아져야하는데, 그런 메모리 버스는 여러 장들을 수용할 공간이 없어서, 고성능 장치들을 CPU에 가깝게 배치하고 느린 성능의 장치들을 그보다 멀리 배치하였다. 멀리 배치하는 것도 많은 장치들을 연결할 수 있다는 장점이 있다.
### B. 표준 장치
일반적인 시스템 구조에서 CPU와 주메모리는 **메모리 버스** 로 연결되어 있다. 몇 가지 장치들이 PCI같은 범용 **I/O 버스** 에 연결이 되어있다. 그래픽이나 다른 고성능 I/O 장치들이 여기에 해당한다. 그리고 그 아래에는 SCSI, SATA, USB와 같은 주변장치용 버스가 있다. 이 버스들에 디스크, 마우스와 같은 가장 느린 장치들이 연결된다.
계층적인 구조가 필요한 이유는 물리학적인 이유와 비용 때문이다. 버스가 고속화하려면 더 짧아져야하는데, 그런 메모리 버스는 여러 장들을 수용할 공간이 없어서, 고성능 장치들을 CPU에 가깝게 배치하고 느린 성능의 장치들을 그보다 멀리 배치하였다. 멀리 배치하는 것도 많은 장치들을 연결할 수 있다는 장점이 있다.
### B. 표준 장치
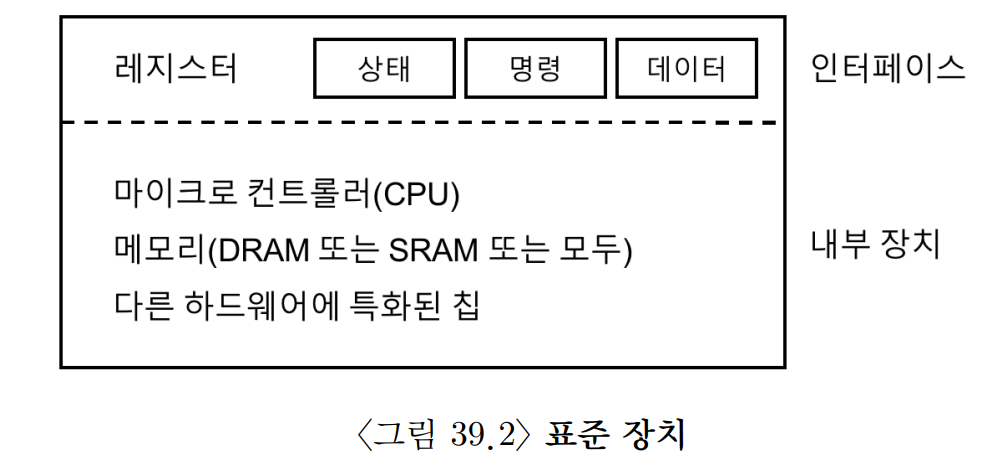 가상의 표준 장치를 효율적으로 활용하기 위해서 중요한 요소가 두 가지 있다.
1. 시스템의 다른 구성 요소에게 제공하는 하드웨어 **인터페이스**
2. **내부 구조**
소프트웨어가 인터페이스를 제공하듯이 하드웨어도 인터페이스를 제공하여 시스템 소프트웨어가 동작을 제어할 수 있도록 해야한다. 그렇기 때문에 모든 하드웨어 장치는 특정한 상호동작을 위한 방식과 명시적인 인터페이스를 갖는다.
또한 시스템에게 제공한 장치에 대한 추상화를 정의하는 내부구조가 필요하다. 최신 RAID 컨트롤러는 수십만 줄에 달하는 **펌웨어(firmware)** 라는 소프트웨어가 하드웨어 내부의 동작을 정의한다.
### C. 표준 방식
단순한 인터페이스는 **상태**, **명령어(command) , 데이터** 레지스터로 구성되어 있다.
상태 레지스터로 장치의 현재 상태를 읽을 수 있고, 명령어 레지스터로 장치가 특정 동작을 수행하도록 요청하고, 데이터 레지스터는 장치와 데이터를 주고받을 수 있다.
장치가 운영체제를 대신하여 특정 동작을 할 때에는 운영체제와 장치 간에 상호 동작 과정이 있다
```jsx
While (STATUS == BUSY);
// 장치가 바쁜 상태가 아닐 때까지 대기
//데이터를 DATA 레지스터에 쓰기
//명령어를 COMMAND 레지스터에 쓰기
(그러면 장치가 명령어를 실행한다)
While (STATUS == BUSY);
// 요청을 처리하여 완료할 때까지 대기
```
방식은 네 단계로 이루어진다.
1. **장치에 폴링(Polling)** : 반복적으로 장치의 상태 레지스터를 읽어서 명령의 수신 가능 여부를 확인한다. (옵저버 패턴??)
2. **데이터 전달** : 운영체제가 데이터 레지스터에 어떤 데이터를 전달한다. 장치는 여러 번의 쓰기를 수행할 것이다. 데이터 전송에 메인 CPU가 관여하는 경우를 **programmed I/O** 라고 부른다.
3. **명령어 쓰기** : 운영체제가 명령 레지스터에 명령어를 기록한다. 이 레지스터에 명령어가 기록되면 데이터는 이미 준비되었다고 판단하고 명령어를 처리한다.
4. **대기** : 운영체제는 디바이스가 처리를 완료했는지를 확인하는 폴링 반복문을 돌면서 기다린다.
이 방법은 간단하지만 매우 비효율적인 방법이다.
첫 번째 문제는 매우 비효율적인 폴링을 사용하고 있다는 점이다.
다른 프로세스에게 CPU를 양도하지 않고, 장치가 동작을 수행하는 동안 계속 루프를 돌면서 장치상태를 체크하고있다. 떄문에 CPU 시간을 매우 낭비하고 있다.
```jsx
핵심 질문 : 폴링 사용 비용을 어떻게 피하는가?
어떻게 하면 자주 폴링을 하지 않으면서 운영체제가 장치의 상태를
확인할 수 있고, 장치를 관리하는 CPU의 오버헤드를 줄일 수 있을까?
```
### D. 인터럽트를 이용한 CPU 오버헤드 개선
**인터럽트**
디바이스를 폴링하는 대신 운영체제는 입출력 작업을 요청한 프로세스를 블록 시키고 CPU를 다른 프로세스에게 양도한다.
장치가 작업을 마치면 하드웨어 인터럽트를 발생시키고 CPU는 운영체제가 미리 정의 해놓은 **인터럽트 서비스 루틴(ISR)** 또는 **인터럽트 핸들러** 를 실행한다.
가상의 표준 장치를 효율적으로 활용하기 위해서 중요한 요소가 두 가지 있다.
1. 시스템의 다른 구성 요소에게 제공하는 하드웨어 **인터페이스**
2. **내부 구조**
소프트웨어가 인터페이스를 제공하듯이 하드웨어도 인터페이스를 제공하여 시스템 소프트웨어가 동작을 제어할 수 있도록 해야한다. 그렇기 때문에 모든 하드웨어 장치는 특정한 상호동작을 위한 방식과 명시적인 인터페이스를 갖는다.
또한 시스템에게 제공한 장치에 대한 추상화를 정의하는 내부구조가 필요하다. 최신 RAID 컨트롤러는 수십만 줄에 달하는 **펌웨어(firmware)** 라는 소프트웨어가 하드웨어 내부의 동작을 정의한다.
### C. 표준 방식
단순한 인터페이스는 **상태**, **명령어(command) , 데이터** 레지스터로 구성되어 있다.
상태 레지스터로 장치의 현재 상태를 읽을 수 있고, 명령어 레지스터로 장치가 특정 동작을 수행하도록 요청하고, 데이터 레지스터는 장치와 데이터를 주고받을 수 있다.
장치가 운영체제를 대신하여 특정 동작을 할 때에는 운영체제와 장치 간에 상호 동작 과정이 있다
```jsx
While (STATUS == BUSY);
// 장치가 바쁜 상태가 아닐 때까지 대기
//데이터를 DATA 레지스터에 쓰기
//명령어를 COMMAND 레지스터에 쓰기
(그러면 장치가 명령어를 실행한다)
While (STATUS == BUSY);
// 요청을 처리하여 완료할 때까지 대기
```
방식은 네 단계로 이루어진다.
1. **장치에 폴링(Polling)** : 반복적으로 장치의 상태 레지스터를 읽어서 명령의 수신 가능 여부를 확인한다. (옵저버 패턴??)
2. **데이터 전달** : 운영체제가 데이터 레지스터에 어떤 데이터를 전달한다. 장치는 여러 번의 쓰기를 수행할 것이다. 데이터 전송에 메인 CPU가 관여하는 경우를 **programmed I/O** 라고 부른다.
3. **명령어 쓰기** : 운영체제가 명령 레지스터에 명령어를 기록한다. 이 레지스터에 명령어가 기록되면 데이터는 이미 준비되었다고 판단하고 명령어를 처리한다.
4. **대기** : 운영체제는 디바이스가 처리를 완료했는지를 확인하는 폴링 반복문을 돌면서 기다린다.
이 방법은 간단하지만 매우 비효율적인 방법이다.
첫 번째 문제는 매우 비효율적인 폴링을 사용하고 있다는 점이다.
다른 프로세스에게 CPU를 양도하지 않고, 장치가 동작을 수행하는 동안 계속 루프를 돌면서 장치상태를 체크하고있다. 떄문에 CPU 시간을 매우 낭비하고 있다.
```jsx
핵심 질문 : 폴링 사용 비용을 어떻게 피하는가?
어떻게 하면 자주 폴링을 하지 않으면서 운영체제가 장치의 상태를
확인할 수 있고, 장치를 관리하는 CPU의 오버헤드를 줄일 수 있을까?
```
### D. 인터럽트를 이용한 CPU 오버헤드 개선
**인터럽트**
디바이스를 폴링하는 대신 운영체제는 입출력 작업을 요청한 프로세스를 블록 시키고 CPU를 다른 프로세스에게 양도한다.
장치가 작업을 마치면 하드웨어 인터럽트를 발생시키고 CPU는 운영체제가 미리 정의 해놓은 **인터럽트 서비스 루틴(ISR)** 또는 **인터럽트 핸들러** 를 실행한다.
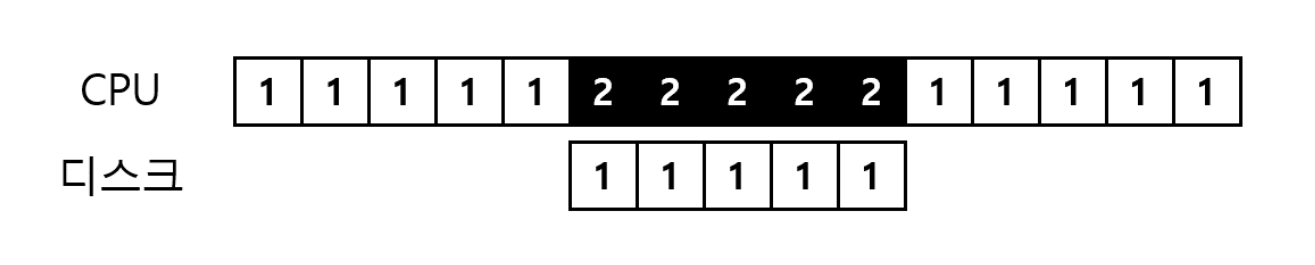 인터럽트가 항상 최적의 해법은 아니다. 대부분의 작업이 한 번의 폴링만으로 끝날 정도로 매우 빠른 장치인 경우, 인터럽트를 사용하면 시스템이 느려진다. 다른 프로세스로 문맥을 교환하고 인터럽트를 처린한 후 다시 I/O르 요청한 프로세스로 문맥 교환하는 것이 매우 비싼 작업이기 때문이다.
따라서 빠른 장치라면 폴링이 최선이고, 느리다면 인터럽트를 사용하여 중첩시키는 것이 최선이다.
### E. DMA를 이용한 효율적인 데이터 이동
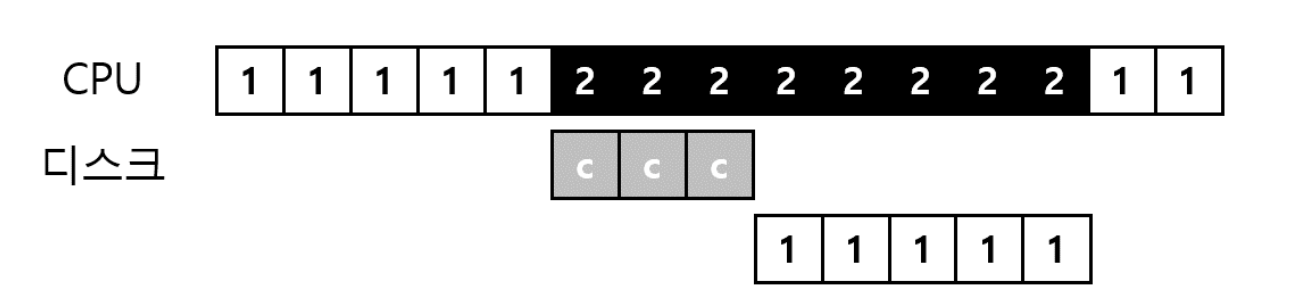
한 프로세스에서 대량의 데이터를 처리하면, 데이터를 메모리에서 디스크로 한 워드씩 복사하느라 CPU가 다시 단순 작업 처리에 소모될 수 있다.
이에 대한 해법이 **직접 메모리 접근 방식 (Direct Memory Access, DMA)** 이다. DMA 엔진은 시스템 내에 있는 특수 장치로서 CPU의 간섭없이 메모리와 장치 간에 전송을 담당한다.
데이터를 전송한다고 했을 때 운영체제는 DMA 엔진에 메모리 상의 데이터 위치와 전송할 데이터의 크기와 대상 장치를 프로그램한다.
인터럽트가 항상 최적의 해법은 아니다. 대부분의 작업이 한 번의 폴링만으로 끝날 정도로 매우 빠른 장치인 경우, 인터럽트를 사용하면 시스템이 느려진다. 다른 프로세스로 문맥을 교환하고 인터럽트를 처린한 후 다시 I/O르 요청한 프로세스로 문맥 교환하는 것이 매우 비싼 작업이기 때문이다.
따라서 빠른 장치라면 폴링이 최선이고, 느리다면 인터럽트를 사용하여 중첩시키는 것이 최선이다.
### E. DMA를 이용한 효율적인 데이터 이동
한 프로세스에서 대량의 데이터를 처리하면, 데이터를 메모리에서 디스크로 한 워드씩 복사하느라 CPU가 다시 단순 작업 처리에 소모될 수 있다.
이에 대한 해법이 **직접 메모리 접근 방식 (Direct Memory Access, DMA)** 이다. DMA 엔진은 시스템 내에 있는 특수 장치로서 CPU의 간섭없이 메모리와 장치 간에 전송을 담당한다.
데이터를 전송한다고 했을 때 운영체제는 DMA 엔진에 메모리 상의 데이터 위치와 전송할 데이터의 크기와 대상 장치를 프로그램한다.
 ### F. 디바이스와 상호작용하는 방법
장치와 통신하는 기본적인 방법은 두 가지이다.
1. **I/O 명령** 을 명시적으로 사용 : **특권** 명령어로 운영체제가 장치를 제어한다.
2. **memory mapped I/O** : 하드웨어가 레지스터들을 메모리 상에 존재하는 것처럼 만든다. 특정 레지스터를 접근하기 위해 운영체제는 해당 주소를 load(읽기) 또는 store(쓰기)를 하면 된다.
### G. 운영체제에 연결하기 : 디바이스 드라이버
최종적인 문제는 서로 다른 인터페이스를 갖는 장치들과 운영체제를 연결시키는 일반적인 방법을 찾는 것이다.
```jsx
핵심 질문 : 어떻게 장치 중립적인 운영체제를 만들까?
어떻게 하면 운영체제를 장치 중립적으로 만들고, 장치와의
상호작용을 위한 상세 내용을 운영체제로부터 숨길 수 있을까?
```
**추상화 (abstraction)** 로 장치와의 상호작용을 캡슐화할 수 있다.
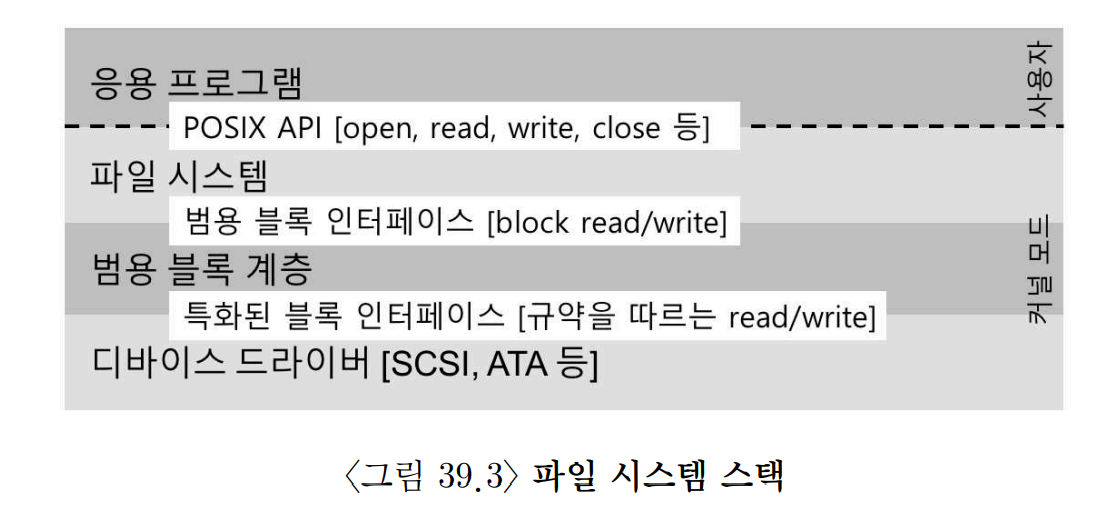
Linux의 파일 시스템 소프트웨어 계층에서도 어떤 디스크 종류를 사용하는지 전혀 알지 못한다. 파일 시스템은 범용 블록 계층에 블럭 read/write 요청을 할 뿐이다.
범용 블럭 계층은 적절한 디바이스 드라이버로 받은 요청을 전달하면, 디바이스 드라이버는 특정 요청을 장치에 내리기 위해 필요한 일들을 처리한다.
### F. 디바이스와 상호작용하는 방법
장치와 통신하는 기본적인 방법은 두 가지이다.
1. **I/O 명령** 을 명시적으로 사용 : **특권** 명령어로 운영체제가 장치를 제어한다.
2. **memory mapped I/O** : 하드웨어가 레지스터들을 메모리 상에 존재하는 것처럼 만든다. 특정 레지스터를 접근하기 위해 운영체제는 해당 주소를 load(읽기) 또는 store(쓰기)를 하면 된다.
### G. 운영체제에 연결하기 : 디바이스 드라이버
최종적인 문제는 서로 다른 인터페이스를 갖는 장치들과 운영체제를 연결시키는 일반적인 방법을 찾는 것이다.
```jsx
핵심 질문 : 어떻게 장치 중립적인 운영체제를 만들까?
어떻게 하면 운영체제를 장치 중립적으로 만들고, 장치와의
상호작용을 위한 상세 내용을 운영체제로부터 숨길 수 있을까?
```
**추상화 (abstraction)** 로 장치와의 상호작용을 캡슐화할 수 있다.
Linux의 파일 시스템 소프트웨어 계층에서도 어떤 디스크 종류를 사용하는지 전혀 알지 못한다. 파일 시스템은 범용 블록 계층에 블럭 read/write 요청을 할 뿐이다.
범용 블럭 계층은 적절한 디바이스 드라이버로 받은 요청을 전달하면, 디바이스 드라이버는 특정 요청을 장치에 내리기 위해 필요한 일들을 처리한다.
 캡슐화도 단점이 존재한다. 다른 특수 기능이 많은 장치가 있을 때, 해당 장치가 보내는 특별한 값을 처리하지 못하기 때문이다.
## Reference
- [Operating Systems: Three Easy Pieces (OSTEP)](https://pages.cs.wisc.edu/~remzi/OSTEP/) by Remzi H. Arpaci-Dusseau and Andrea C. Arpaci-Dusseau
캡슐화도 단점이 존재한다. 다른 특수 기능이 많은 장치가 있을 때, 해당 장치가 보내는 특별한 값을 처리하지 못하기 때문이다.
## Reference
- [Operating Systems: Three Easy Pieces (OSTEP)](https://pages.cs.wisc.edu/~remzi/OSTEP/) by Remzi H. Arpaci-Dusseau and Andrea C. Arpaci-Dusseau